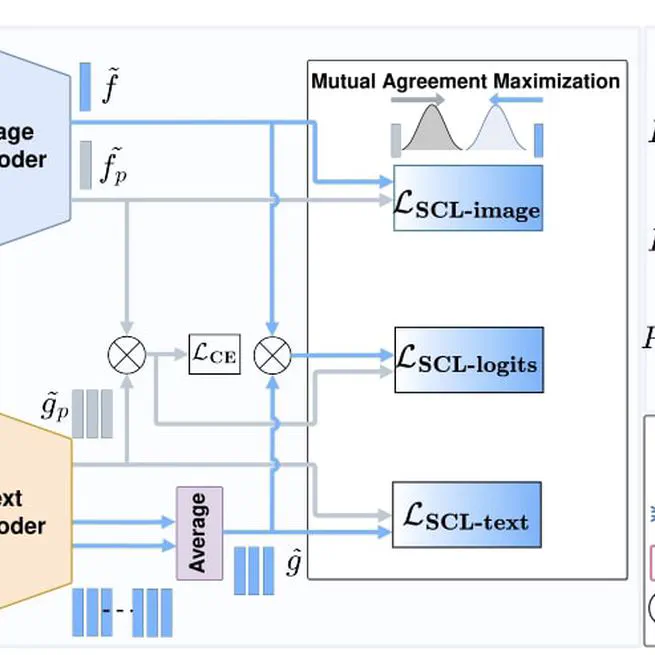
Self-regulating Prompts: Foundational Model Adaptation without Forgetting
**Vision-Language Model**, **ICCV 2023** Self-regularization for foundational vision-language models during fine-tuning.
Jul 13, 2023
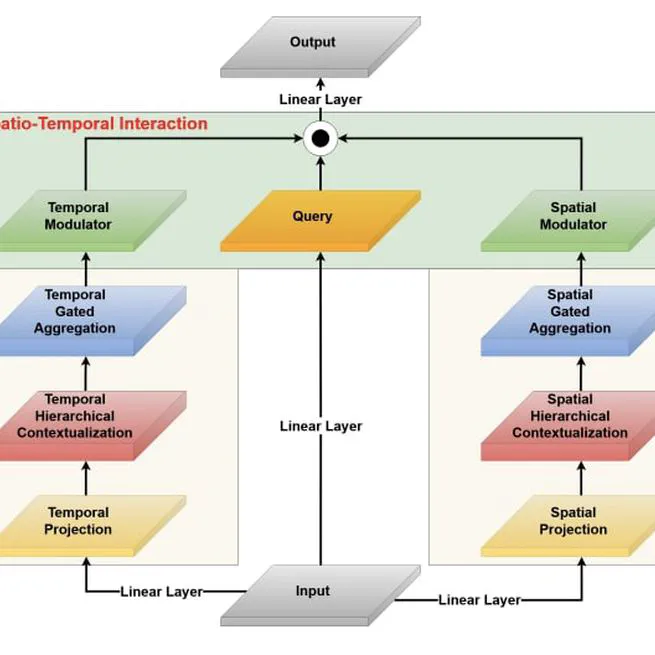
Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition
**Visual-Spatial and Temporal Perception**, **ICCV 2023** Spatio-temporal focal modulation for video recognition is an efficient network.
Jul 13, 2023
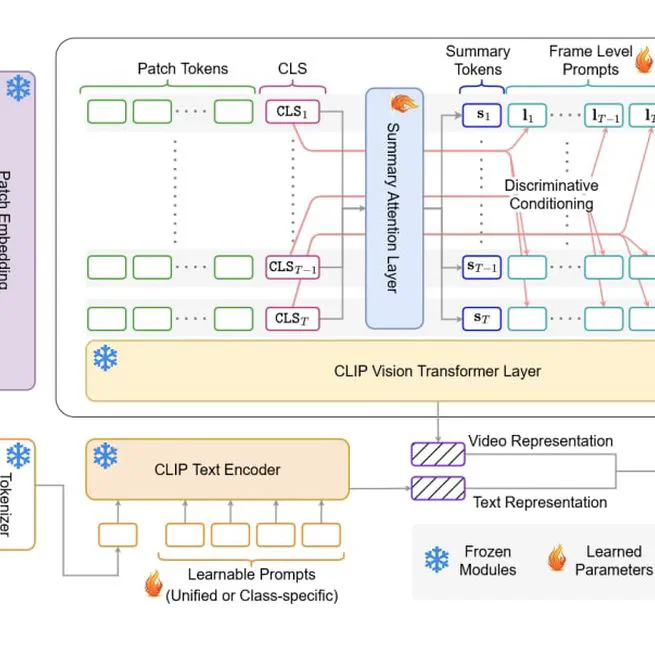
Vita-CLIP: Video and text adaptive CLIP via Multimodal Prompting
**Vision-Language Model**, **CVPR 2023** Adapting vision language Foundational models like CLIP for video recognition.
Feb 27, 2023