Boosting Adversarial Transferability using Dynamic Cues
Feb 1, 2023· ,,,·
0 min read
,,,·
0 min read
Muzammal Naseer
Ahmad Mahmood
Salman Khan
Fahad Shahbaz Khan
Abstract
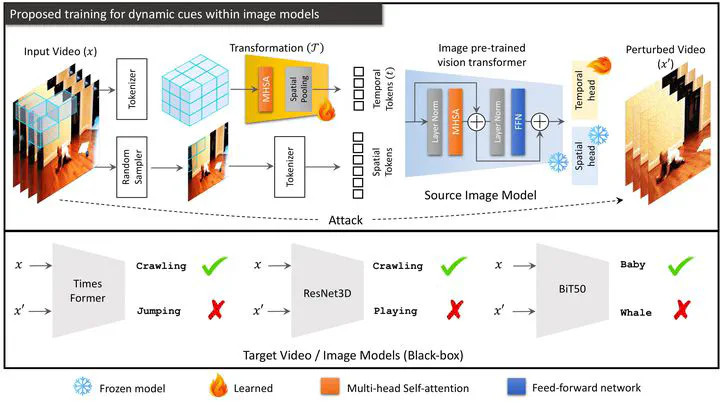
Deep neural networks are vulnerable to adversarial attacks. We can develop more reliable AI models by analyzing blind spots across different architectures, datasets, and tasks using transferable adversarial attacks. This year ICLR'23, we will present a method to study adversarial blind spots of video models by transferring adversarial perturbations from Image to Video and Multi-view models. We show that we can re-configure a pre-trained Vision Transformer (ViT) by inducing dynamic cues to give the model the ability to recognize an action in a video (e.g., Kinetics) or a 3D object (e.g., ModelNet40 ) without losing the original pre-trained image solution (e.g., ImageNet). Therefore, we do not need specialized architectures, e.g., divided space-time attention, 3D convolutions, or multi-view convolution networks for different data modalities. Image models are effective surrogates to optimize an adversarial attack to fool black-box models in a changing environment over time.We analyze 16 architectures across seven large-scale image and video datasets using three types of pre-trained models (supervised, self-supervised, and text-supervised).
Type
Publication
In * International Conference on Learning Representations, ICLR 2023*