FLIP: Cross-domain Face Anti-spoofing with Language Guidance
Jul 13, 2023· ,·
0 min read
,·
0 min read
Koushik Srivatsan
Muzammal Naseer
Karthik Nandakumar
Abstract
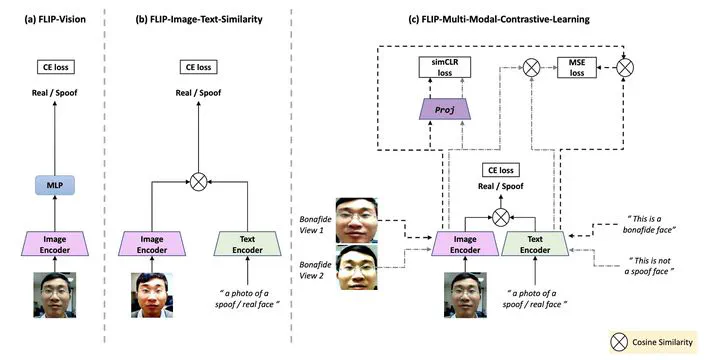
Face anti-spoofing (FAS) or presentation attack detection is an essential component of face recognition systems deployed in security-critical applications. Existing FAS methods have poor generalizability to unseen spoof types, camera sensors, and environmental conditions. Recently, vision transformer (ViT) models have been shown to be effective for the FAS task due to their ability to capture longrange dependencies among image patches. However, adaptive modules or auxiliary loss functions are often required to adapt pre-trained ViT weights learned on large-scale datasets such as Imagenet. In this work, we first show that initializing ViTs with multi-modal (e.g., CLIP) pre-trained weights improves generalizability for the FAS task, which is in line with the zero-shot transfer capabilities of vision-language pretrained (VLP) models. We then propose a novel approach for robust cross-domain FAS by grounding visual representations with the help of natural language. Specifically, we show that aligning the image representation with an ensemble of class descriptions (based on natural language semantics) improves FAS generalizability in low-data regimes. Finally, we propose a multi-modal contrastive learning strategy to further boost the feature generalization and bridge the gap between source and target domains. Extensive experiments on three standard protocols demonstrate that our method significantly outperforms the state-of-the-art methods, achieving better zero-shot transfer performance than five-shot transfer of “adaptive ViTs”. Our code and pre-trained models are publicly available at here
Type
Publication
In * International Conference on Computer Vision, ICCV 2023*