Self-supervised Video Transformer
Feb 1, 2022· ,,,·
0 min read
,,,·
0 min read
Kanchana Ranasinghe
Muzammal Naseer
Salman Khan
Fahad Shahbaz Khan
Michael Ryoo
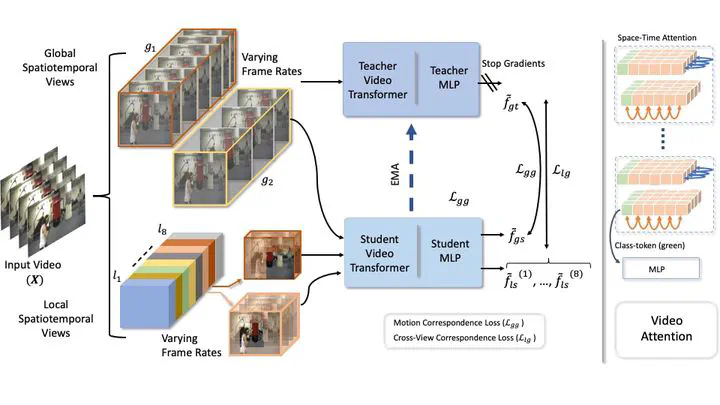
Abstract
In this paper, we propose self-supervised training for video transformers using unlabelled video data. From a given video, we create local and global spatiotemporal views with varying spatial sizes and frame rates. Our self-supervised objective seeks to match the features of these different views representing the same video, to be invariant to spatiotemporal variations in actions. To the best of our knowledge, the proposed approach is the first to alleviate the dependency on negative samples or dedicated memory banks in Self-supervised Video Transformer (SVT). Further, owing to the flexibility of Transformer models, SVT supports slow-fast video processing within a single architecture using dynamically adjusted positional encodings and supports long-term relationship modeling along spatiotemporal dimensions. Our approach performs well on four action recognition benchmarks (Kinetics-400, UCF-101, HMDB-51, and SSv2) and converges faster with small batch sizes. Code is available at here
Type
Publication
In * Conference on Computer Vision and Pattern Recognition, CVPR 2022*