Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition
Jul 13, 2023·, ,,,·
0 min read
,,,·
0 min read
Syed Talal Wasim
Muhammad Uzair Khattak
Muzammal Naseer
Salman Khan
Mubarak Shah
Fahad Shahbaz Khan
Abstract
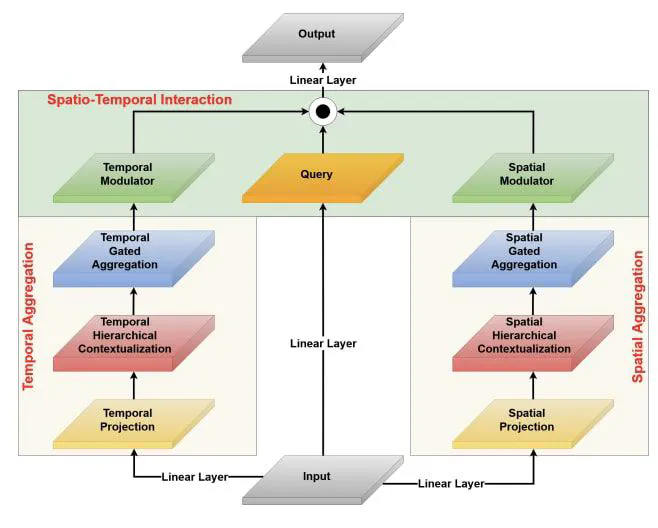
Recent video recognition models utilize Transformer models for long-range spatio-temporal context modeling. Video transformer designs are based on self-attention that can model global context at a high computational cost. In comparison, convolutional designs for videos offer an efficient alternative but lack long-range dependency modeling. Towards achieving the best of both designs, this work proposes Video-FocalNet, an effective and efficient architecture for video recognition that models both local and global contexts. Video-FocalNet is based on a spatio-temporal focal modulation architecture that reverses the interaction and aggregation steps of self-attention for better efficiency. Further, the aggregation step and the interaction step are both implemented using efficient convolution and element-wise multiplication operations that are computationally less expensive than their self-attention counterparts on video representations. We extensively explore the design space of focal modulation-based spatio-temporal context modeling and demonstrate our parallel spatial and temporal encoding design to be the optimal choice. Video-FocalNets perform favorably well against the state-of-the-art transformer-based models for video recognition on three large-scale datasets (Kinetics-400, Kinetics-600, and SS-v2) at a lower computational cost. Our code and pre-trained models are publicly available at here
Type
Publication
In * International Conference on Computer Vision, ICCV 2023*